When building sillytui, a terminal UI for interacting with LLMs, I needed a way to count tokens to manage context windows. Some API backends support tokenization endpoints, but most don’t. Normally you’d call OpenAI’s tiktoken library to do this. But calling Python from C for every message felt wrong. So I asked myself: how hard could it be to implement tiktoken in pure C?
Turns out, not that hard. And because we’re doing it on C, maybe we can make it faster than the original?
Results
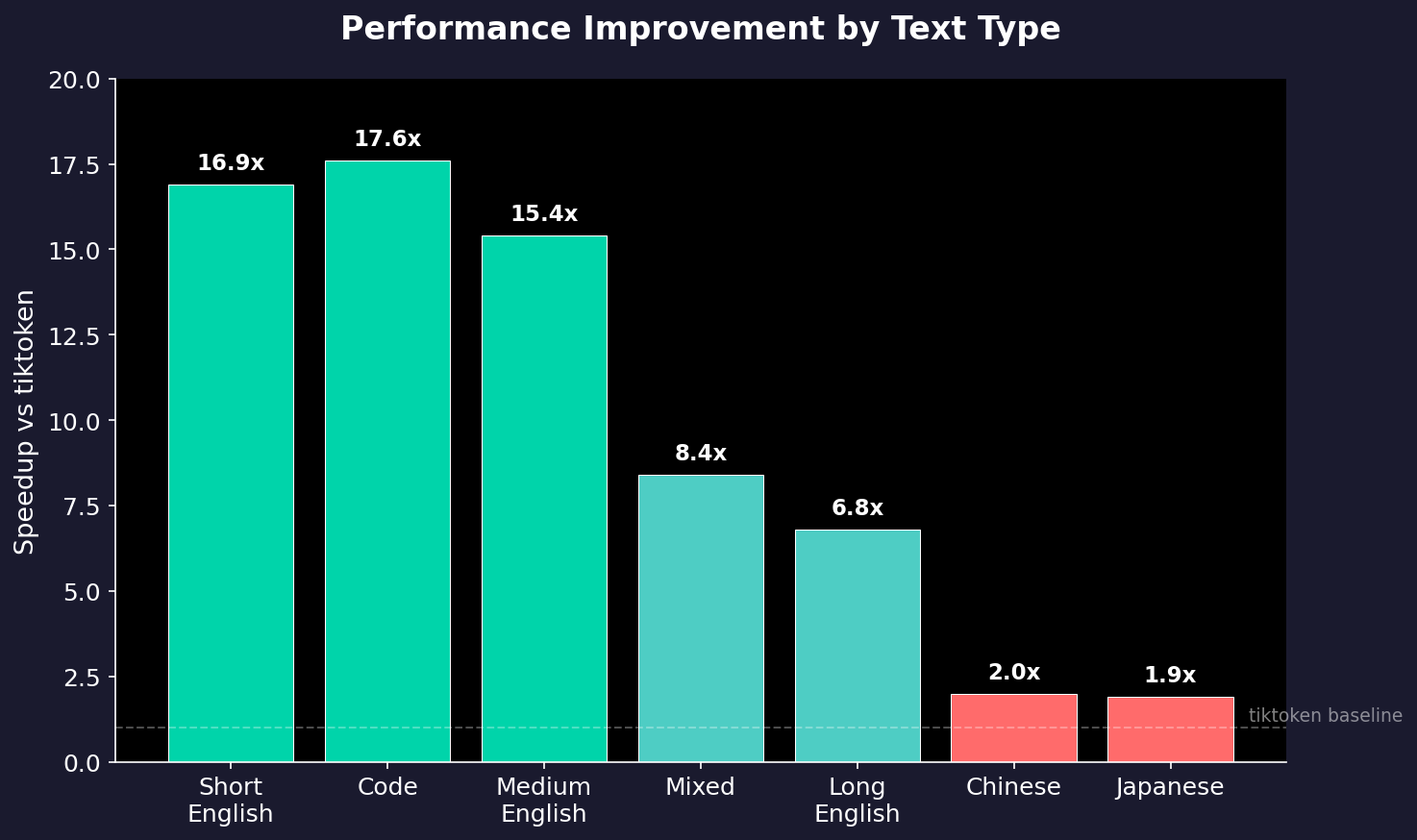
First, let’s look at the results:
| Text Type | tiktoken (Python) | Our C + SIMD | Speedup |
|---|---|---|---|
| Short English | 1.52 µs | 0.09 µs | 16.9x |
| Code | 6.85 µs | 0.39 µs | 17.6x |
| Long English | 12.14 µs | 1.78 µs | 6.8x |
| Japanese | 2.77 µs | 1.45 µs | 1.9x |
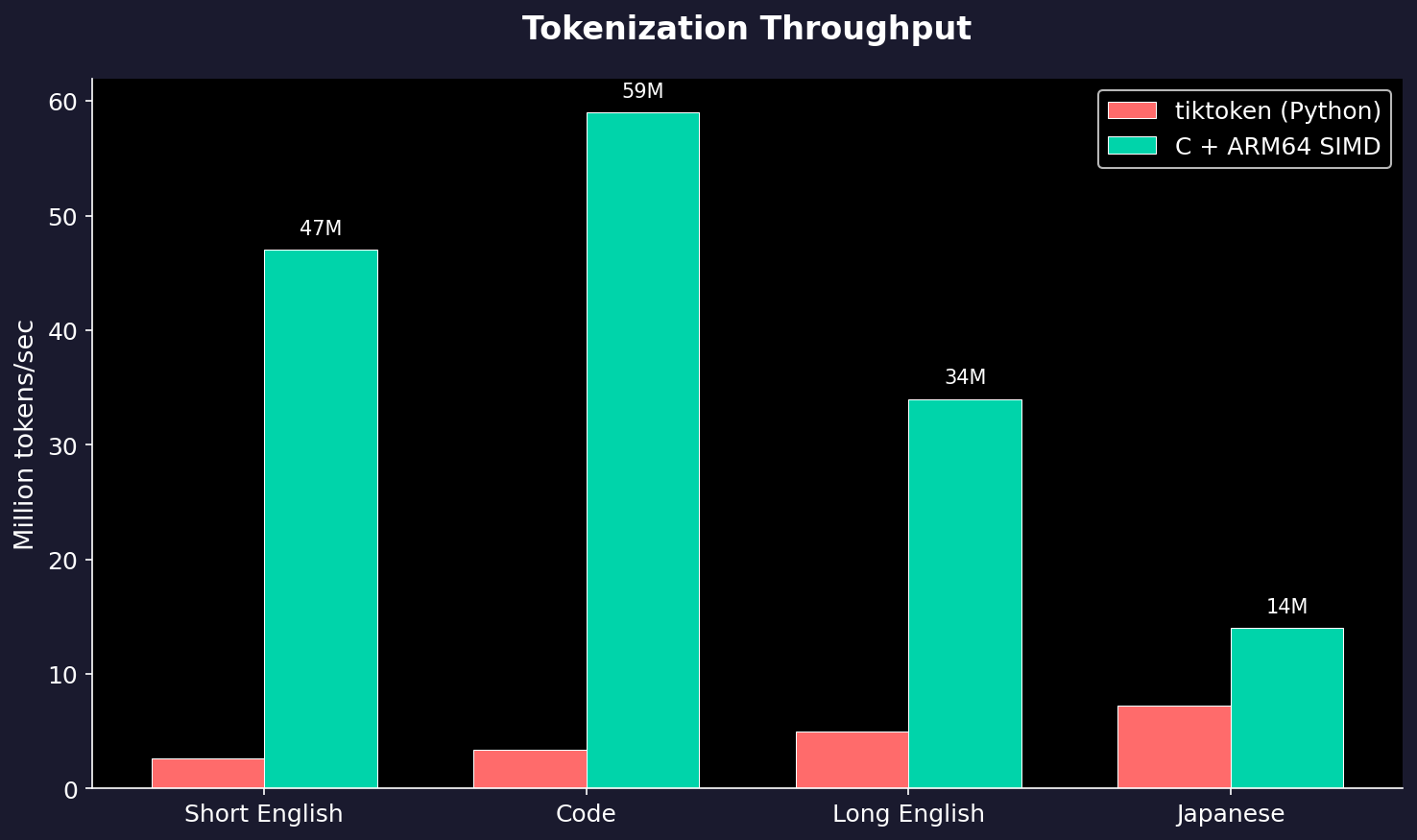
That’s 61 million tokens per second for English text. On a single core, and no GPU.
Part 1: Understanding tiktoken
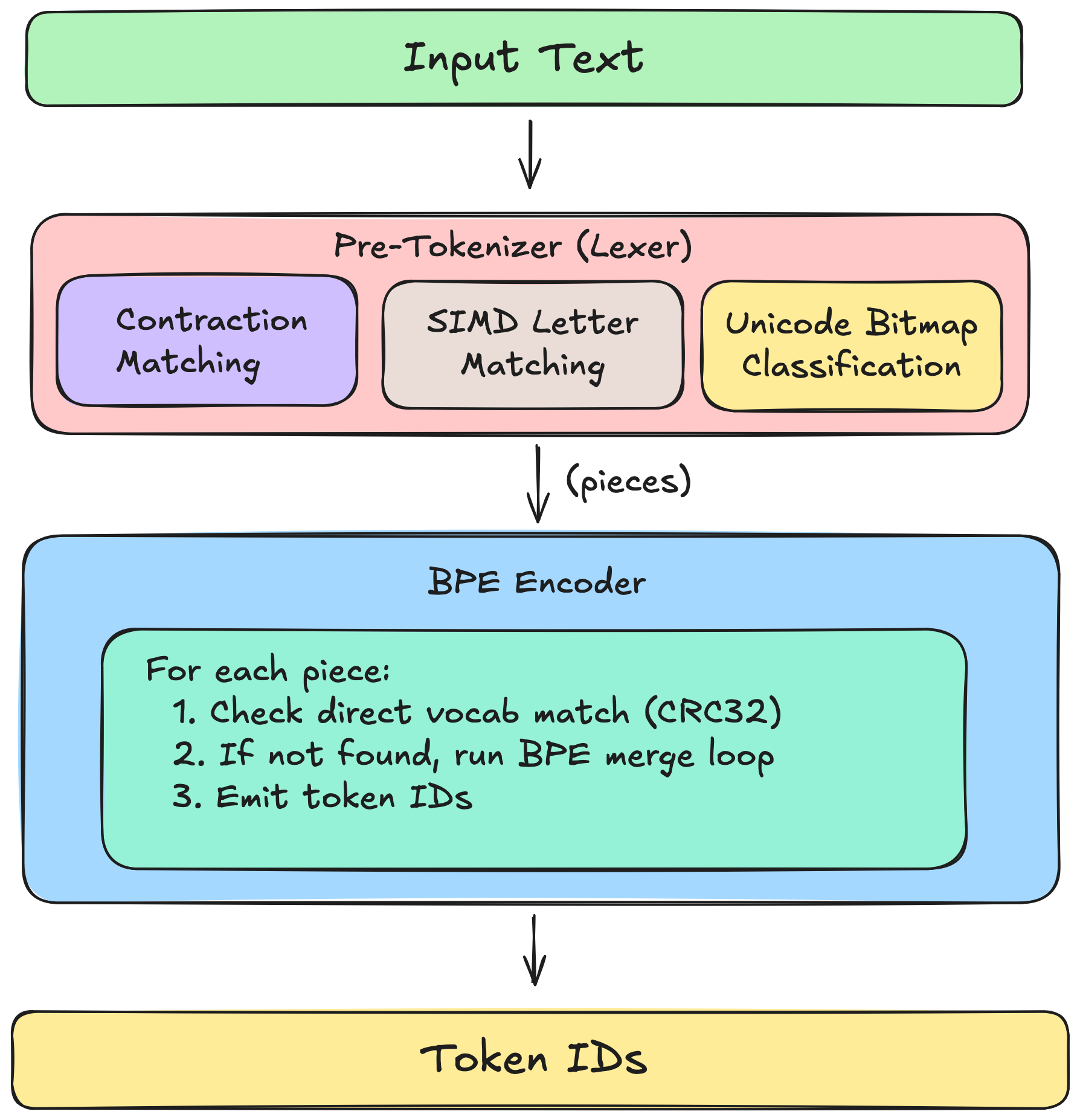
tiktoken uses a two-stage process:
Stage 1: Pre-tokenization
First, text is split into “pieces” using a regex pattern. For GPT-4’s cl100k_base encoding, that pattern is:
(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+
This handles English contractions (don't → don + 't), words, numbers, punctuation, and whitespace, each becoming a separate “piece.”
Stage 2: BPE Encoding
Each piece is then encoded using Byte Pair Encoding (BPE). The algorithm repeatedly merges the most frequent adjacent byte pairs until no more merges are possible:
"hello" → [104, 101, 108, 108, 111] (bytes)
→ [he, 108, 108, 111] (merge h+e)
→ [he, ll, 111] (merge l+l)
→ [he, llo] (merge ll+o)
→ [hello] (merge he+llo)
The vocabulary (100,256 tokens for cl100k) tells us which merges are valid and their priority.
Part 2: The Naive Implementation
My first pass was straightforward C. Essentially, load the vocab, implement the regex as a state machine, then run BPE:

Three things stood out: 1) Token lookup was O(n); linear search through 100K entries for every lookup; 2) Unicode classification was expensive; checking if a character is a “letter” meant binary searching through 200+ Unicode ranges; 3) Everything was byte-by-byte; no vectorization at all.
Part 3: The Hash Table
The first fix was quite simple; use a hash table for token lookup. But which hash function?
We could use FNV-1a, a simple and fast software hash:
uint64_t hash_fnv1a(const uint8_t *bytes, size_t len) {
uint64_t hash = 14695981039346656037ULL;
for (size_t i = 0; i < len; i++) {
hash ^= bytes[i];
hash *= 1099511628211ULL;
}
return hash;
}
But ARM64 has hardware CRC32 support. The crc32x instruction computes a CRC32 checksum of 8 bytes in a single cycle.
_simd_hash_bytes_arm64:
mov w2, #0xFFFFFFFF
.loop8:
cmp x1, #8
b.lt .loop1
ldr x3, [x0], #8 ; Load 8 bytes
crc32x w2, w2, x3 ; CRC32 in ONE cycle
sub x1, x1, #8
b .loop8
; ... handle remaining bytes ...
The results were quite dramatic:
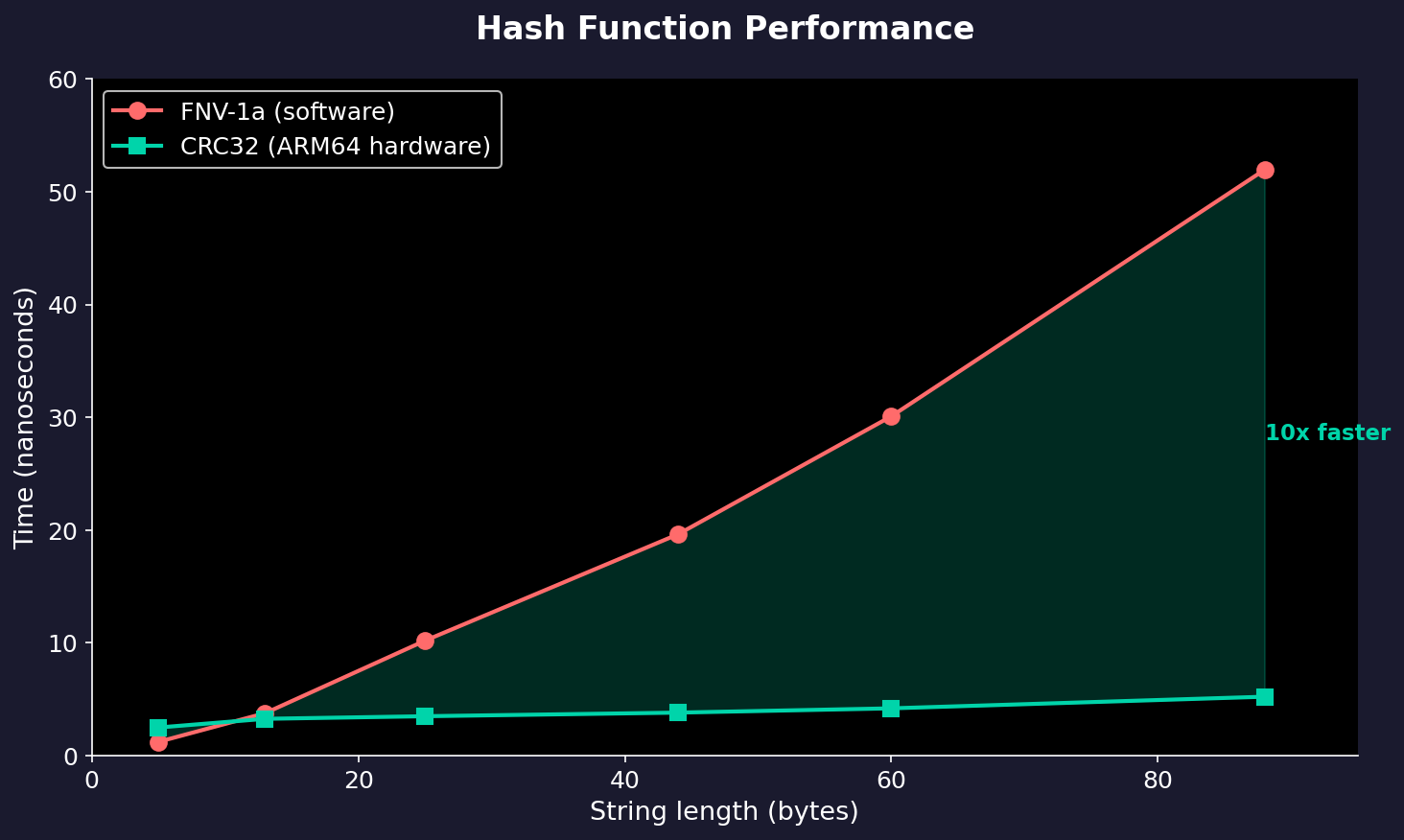
For longer tokens (which are common in vocabularies), CRC32 is 10x faster than FNV-1a.
Part 4: Unicode Bitmaps
The pre-tokenizer needs to classify characters: Is this a letter? A number? Whitespace? Unicode defines hundreds of ranges for these categories.
The naive approach uses binary search:
// 200+ ranges to search through
static const Range LETTER_RANGES[] = {
{0x0041, 0x005A}, // A-Z
{0x0061, 0x007A}, // a-z
{0x00C0, 0x00D6}, // Latin Extended
// ... 200 more ...
};
bool is_letter(uint32_t cp) {
return binary_search(LETTER_RANGES, cp); // O(log n)
}
But 99% of text is ASCII or common Unicode. What if we precomputed the answers?
I ended up generating two data structures:
- ASCII table (128 bytes): Direct lookup for ASCII
- BMP bitmap (8KB): One bit per codepoint for Unicode 0x0000-0xFFFF
// Generated at build time
const uint8_t UNICODE_ASCII_LETTER[128] = {
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, // 0x00-0x0F
// ...
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, // 0x30-0x3F
0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, // 0x40-0x4F (@,A-O)
1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0, // 0x50-0x5F (P-Z,...)
0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, // 0x60-0x6F (`,a-o)
1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0, // 0x70-0x7F (p-z,...)
};
const uint8_t UNICODE_BMP_LETTER[8192] = { /* 65536 bits */ };
static inline bool unicode_is_letter(uint32_t cp) {
if (cp < 128)
return UNICODE_ASCII_LETTER[cp]; // O(1)
if (cp < 0x10000)
return (UNICODE_BMP_LETTER[cp >> 3] >> (cp & 7)) & 1; // O(1)
return binary_search(...); // Rare: only for emoji, etc.
}
This simple change gave us a 2x speedup on English text.
Part 5: SIMD Letter Matching
The pre-tokenizer spends a lot of time matching runs of letters (i.e., words). Processing one byte at a time is wasteful when we have 128-bit NEON registers.
Instead, we could load 16 bytes, check if they’re all ASCII letters, advance by 16 if so.
_simd_match_ascii_letters_arm64:
; Load 16 bytes
ld1 {v0.16b}, [x0]
; Check uppercase: 'A' <= byte <= 'Z'
movi v1.16b, #0x40 ; 'A' - 1
movi v2.16b, #0x5B ; 'Z' + 1
cmhi v3.16b, v0.16b, v1.16b ; byte > 0x40?
cmhi v4.16b, v2.16b, v0.16b ; byte < 0x5B?
and v3.16b, v3.16b, v4.16b ; uppercase mask
; Check lowercase: 'a' <= byte <= 'z'
movi v1.16b, #0x60
movi v2.16b, #0x7B
cmhi v4.16b, v0.16b, v1.16b
cmhi v5.16b, v2.16b, v0.16b
and v4.16b, v4.16b, v5.16b ; lowercase mask
; Combine
orr v3.16b, v3.16b, v4.16b
; Check if ALL 16 bytes are letters
uminv b4, v3.16b ; min across lanes
umov w3, v4.b[0]
cbz w3, .find_boundary ; if min=0, not all letters
; All 16 are letters! Advance and continue
add x0, x0, #16
add x2, x2, #16
b .loop
uminv (unsigned minimum across vector) tells us if any byte failed the letter check. If all 16 passed, we advance by 16. If not, we fall back to finding the exact boundary.
As a result, matching “Supercalifragilisticexpialidocious” takes 3 nanoseconds.
Part 6: Inline String Comparison
Hash table lookups need to compare token bytes on collision. The standard memcmp works, but has function call overhead. For short strings (2-8 bytes, which covers most tokens), we can do better:
static inline bool bytes_equal(const uint8_t *a, const uint8_t *b, size_t len) {
switch (len) {
case 2: return *(uint16_t*)a == *(uint16_t*)b;
case 3: return *(uint16_t*)a == *(uint16_t*)b && a[2] == b[2];
case 4: return *(uint32_t*)a == *(uint32_t*)b;
case 5: return *(uint32_t*)a == *(uint32_t*)b && a[4] == b[4];
case 6: return *(uint32_t*)a == *(uint32_t*)b &&
*(uint16_t*)(a+4) == *(uint16_t*)(b+4);
case 7: return *(uint32_t*)a == *(uint32_t*)b &&
*(uint16_t*)(a+4) == *(uint16_t*)(b+4) && a[6] == b[6];
case 8: return *(uint64_t*)a == *(uint64_t*)b;
default: return memcmp(a, b, len) == 0;
}
}
Each case compiles to just a few instructions.
Part 7: The Architecture
The Results, Again
After all optimizations, here’s where we landed:
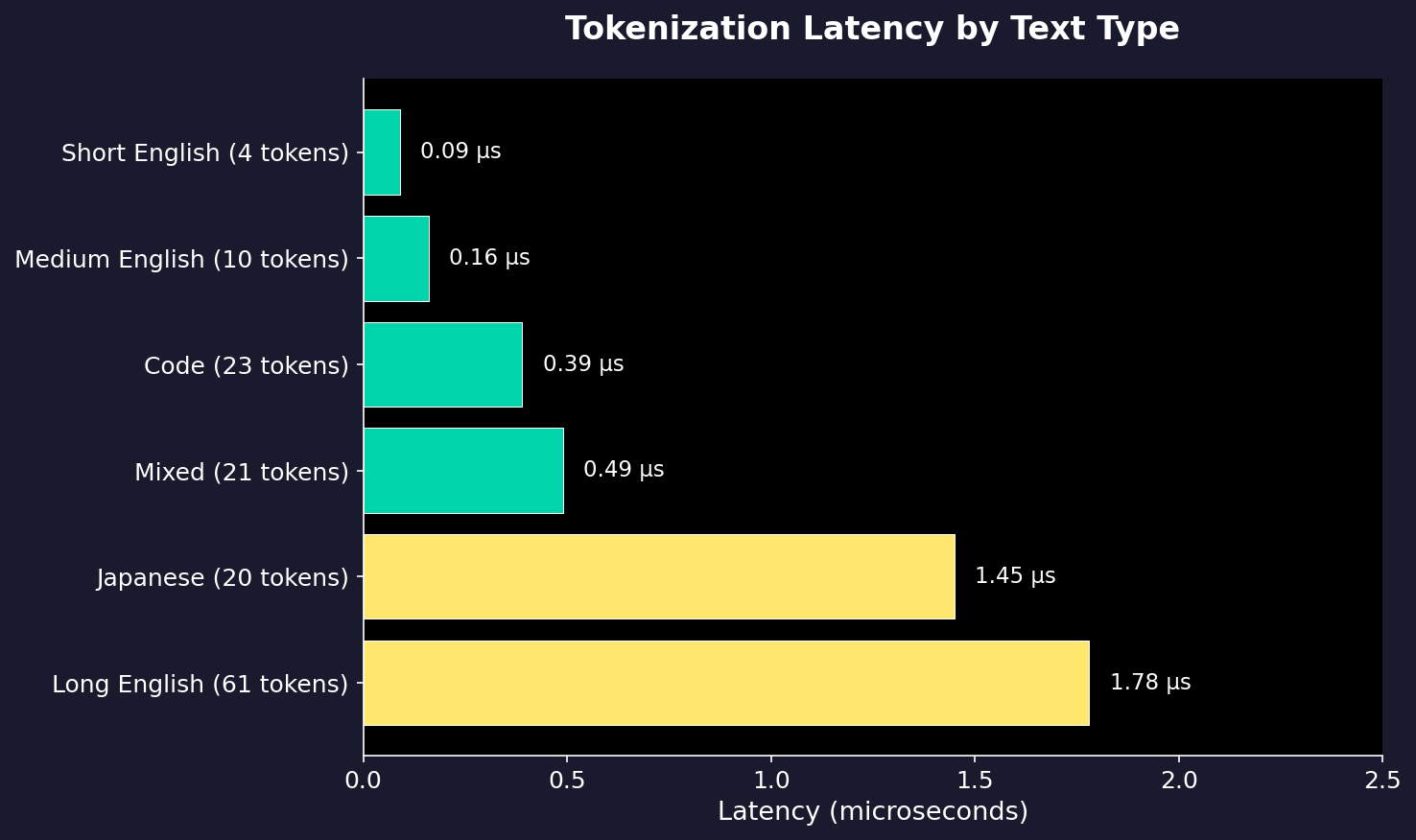
Throughput by Text Type
| Text Type | Tokens/sec | Latency |
|---|---|---|
| Short English | 47M | 0.09 µs |
| Code | 59M | 0.39 µs |
| Long English | 34M | 1.78 µs |
| Japanese | 14M | 1.45 µs |
| Chinese | 15M | 1.66 µs |
Speedup vs tiktoken
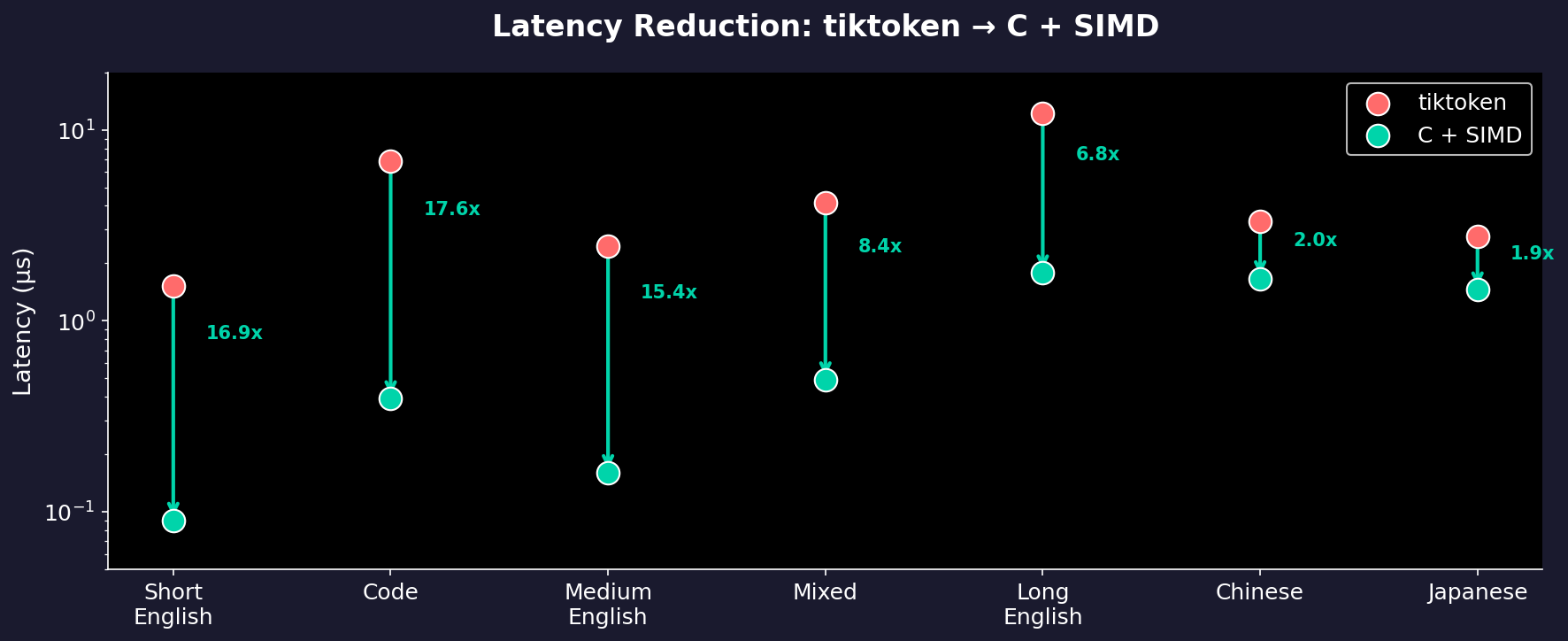
The biggest wins are on ASCII-heavy text (English, code) where our SIMD optimizations shine. CJK text still sees 2x improvement, but the BPE algorithm itself becomes the bottleneck there.
Memory Usage
| Component | Size |
|---|---|
| Vocabulary | ~12 MB |
| Hash table | ~10 MB |
| Unicode bitmaps | 16 KB |
| Total | ~22 MB |
Not bad for a tokenizer that loads in 7ms.
Try It Yourself
The code is part of sillytui. The tokenizer module is self-contained and can be extracted for other projects.
#include "tokenizer.h"
Tokenizer tok;
tokenizer_init(&tok);
tokenizer_load_tiktoken(&tok, "cl100k_base.tiktoken");
int count = tokenizer_count_tokens(&tok, "Hello, world!");
// count = 4
tokenizer_free(&tok);
The implementation automatically uses SIMD on ARM64 and falls back to portable C on other platforms. I will probably add SIMD for x86-64 and RISCV64 in the future, but for now it’s just ARM64. There’s also the option to use a priority queue for BPE, and replace O(n) min-finding with O(log n) heap. But that can be done later. For now, 61M tok/s is plenty fast.
Benchmarks performed on Apple M4 Silicon. Your results may vary.